

While exploring AI use cases, I discovered Retrieval-Augmented Generation (RAG). This technique in natural language processing merges information retrieval with text generation. By doing so, it boosts the abilities of language models to generate responses not just from their pre-trained knowledge but also by sourcing information from contextually relevant documents, leading to more accurate, precise, and timely replies.
In this article, I will experiment with building a generative AI agent using AWS Bedrock to help me in comparing different models of plug-in hybrid SUV available in the market . I already short-listed a few car makers’ models and I want the agent to tailor its responses from these models only. To do so, I will build a knowledge base and populate it with information like catalogues and brochures of these SUVs, in hope that the agent can help me to make a better buying decision.
How RAG works
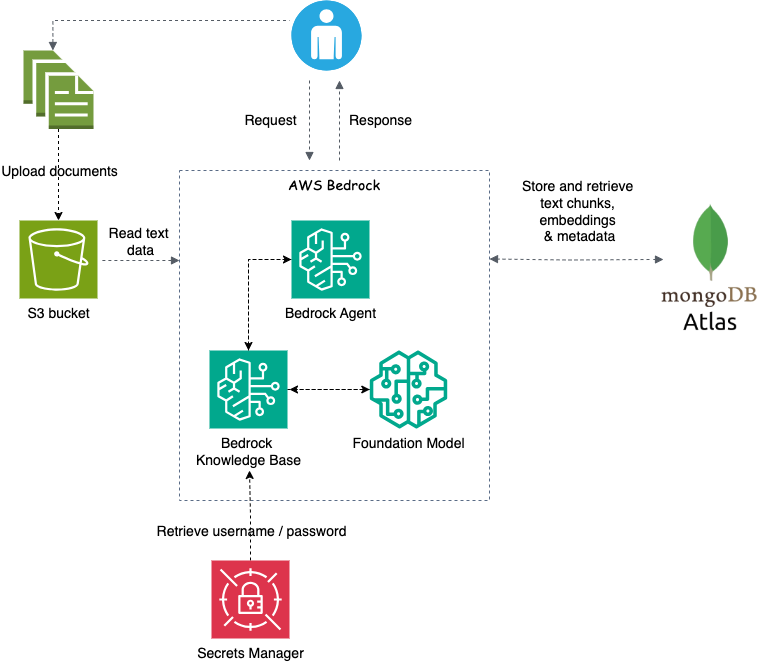
Large Language Model (LLM) are trained on vast volumes of data and use billions of parameters to generate output for tasks like answering questions. RAG optimizes LLM output by referencing a knowledge base outside of its training data source before generating a response.
Data Ingestion: With AWS Bedrock, you build a knowledge base by populating it with external data (e.g. documents uploaded to a S3 bucket). These documents are split into chunks, converted to embeddings, and stored within a vector database (e.g. Mongodb Atlas).
Information Retrieval: When user asks a question, the embedded foundation model in AWS Bedrock utilizes the vector index in the database to find the most relevant documents that match the query. The model then uses these information with its training data to generate a more relevant and up-to-date response for the user.
Foundation Models
AWS Bedrock supports a range of foundation models from Amazon’s own Titan models to other AI companies and in this setup I will try with both the Titan Embeddings G1 – Text and Claude 3 by Anthropic. They are both ideal for open-ended text generation and conversation chat, and supporting RAG.
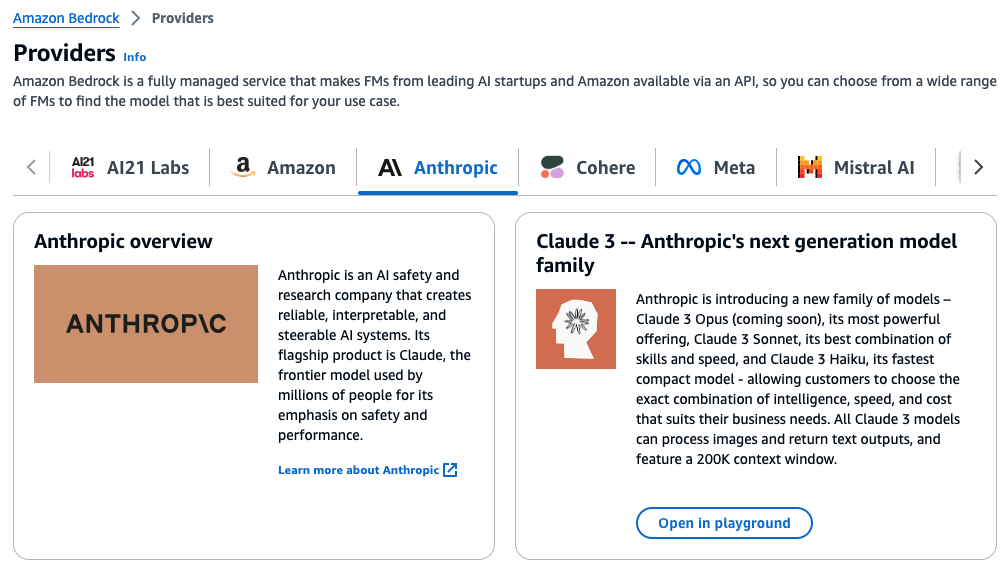

To request access for models, go to AWS Bedrock console and choose Model access, and select the models you want to try.
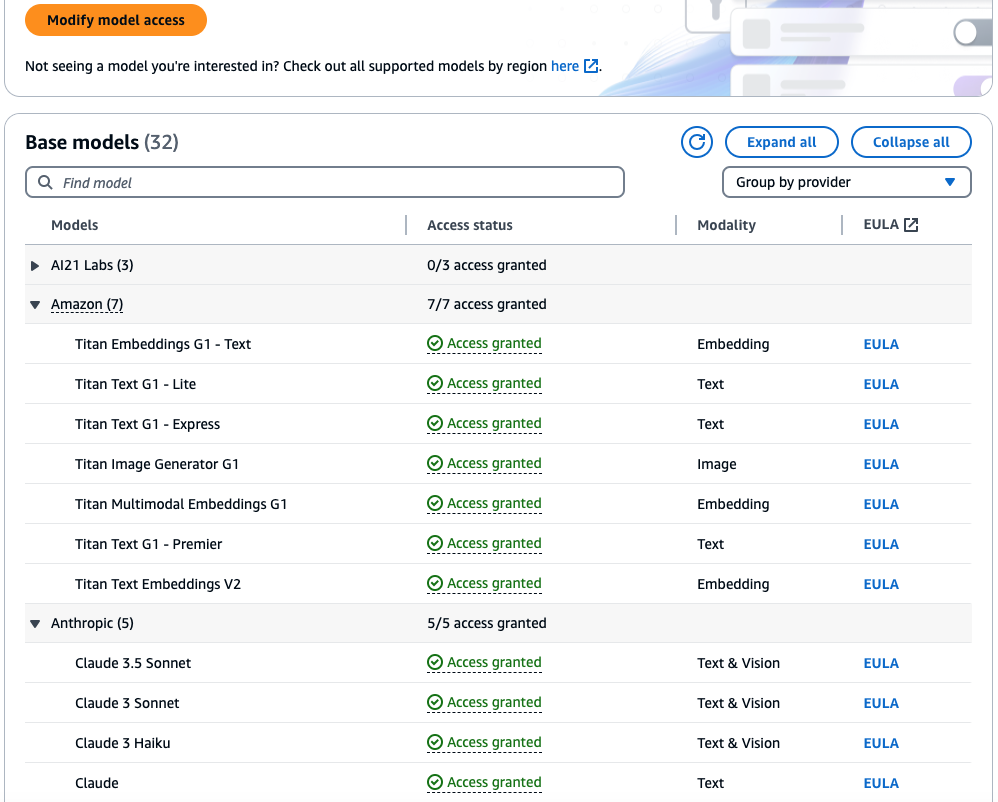
Data Source for Knowledge Base
To prepare the data, I download brochures and catalogues of different car makers’ PHEV SUVs that are available in the market with similar price range, and upload them to a S3 bucket. AWS Bedrock knowledge base supports the following document file formats:
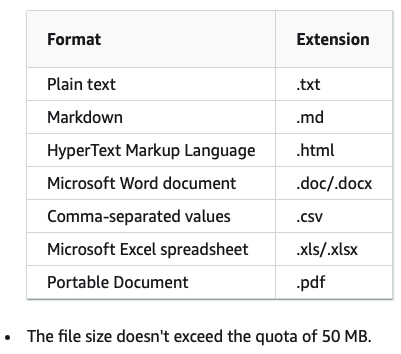
I create a new S3 bucket for storing my documents.
Create a AWS Bedrock Knowledge Base
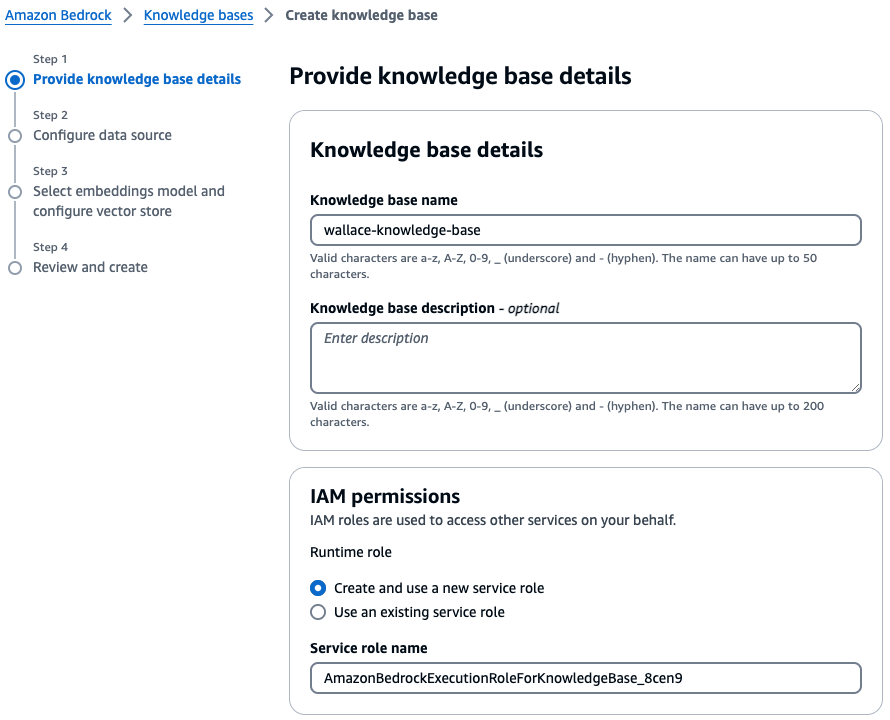
To create a knowledge base, go to AWS Bedrock console and choose Knowledge base
(Note: You must not sign in as root as it cannot create a knowledge base)
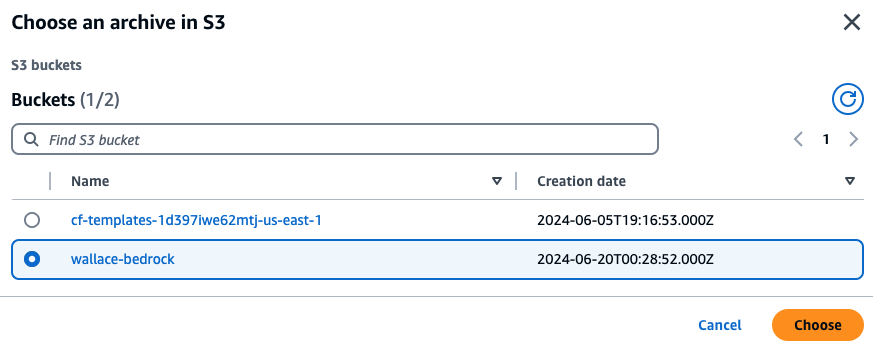
Use the S3 bucket just created as the data source
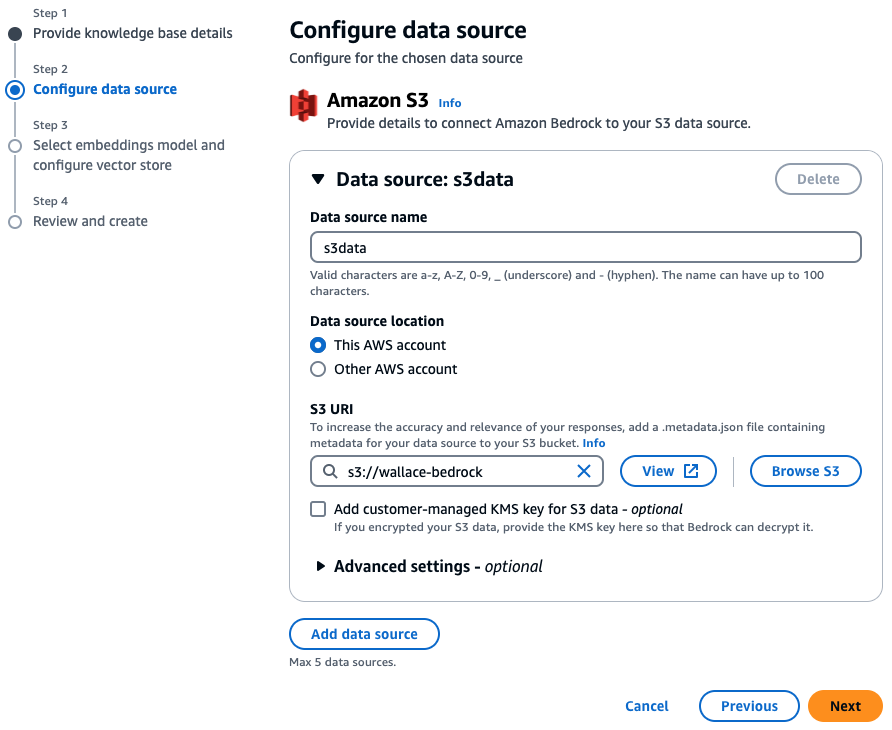
Now choose ‘Titan Embeddings G1 – Text‘ as the embeddings model for converting the documents in S3 into chunks in our vector database.
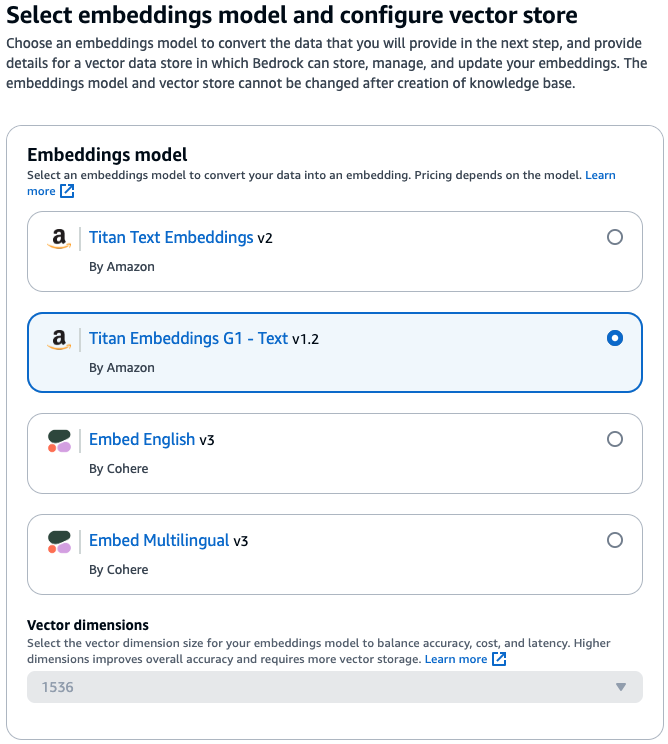
Note: AWS introduced the newer Titan Text Embeddings v2 model in April 2024 and states that it is optimized for RAG, however when I tried to use this model, it failed to create the vector store with using MongoDB Atlas.
AWS Bedrock supports a wide range of vector databases including its own Amazon OpenSearch, but in this setup I will use MongoDB Atlas for its quick, easy deployment and optimized performance.
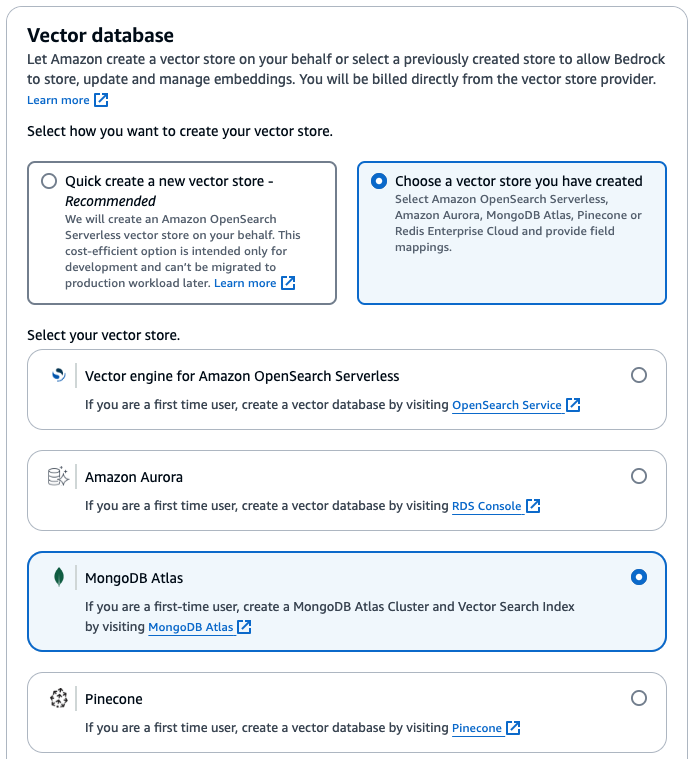
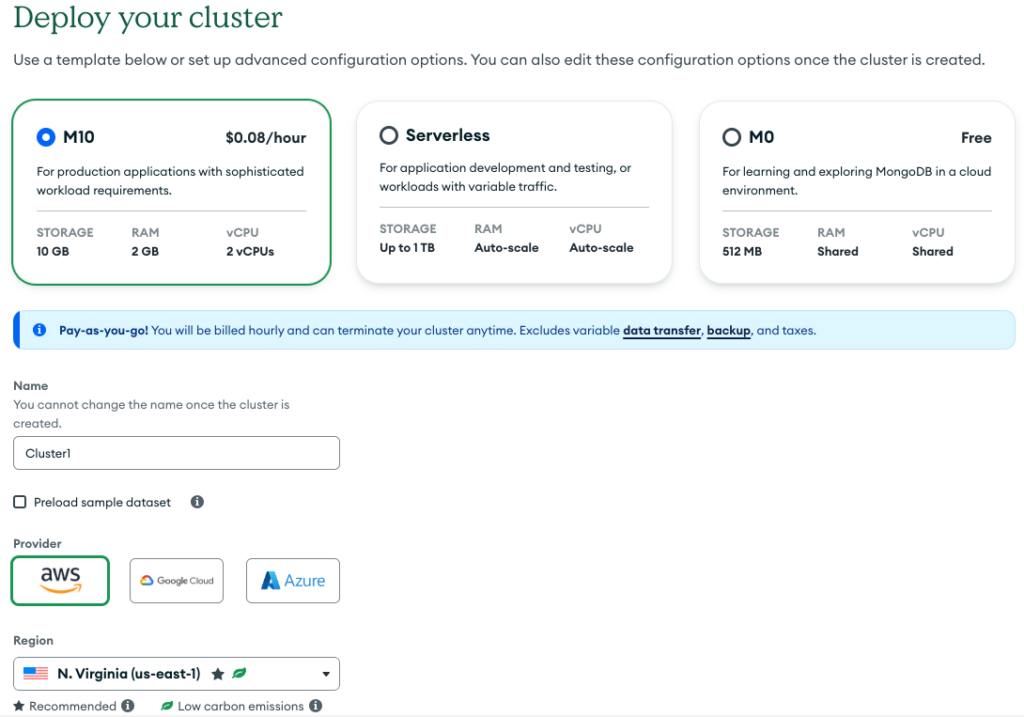
Sign Up for MongoDB Atlas
Login or Signup an account to MongoDB Atlas for an account. Create a MongoDB Atlas cluster with a M10 configuration (M0 free cluster will not work) and setup user and network access.
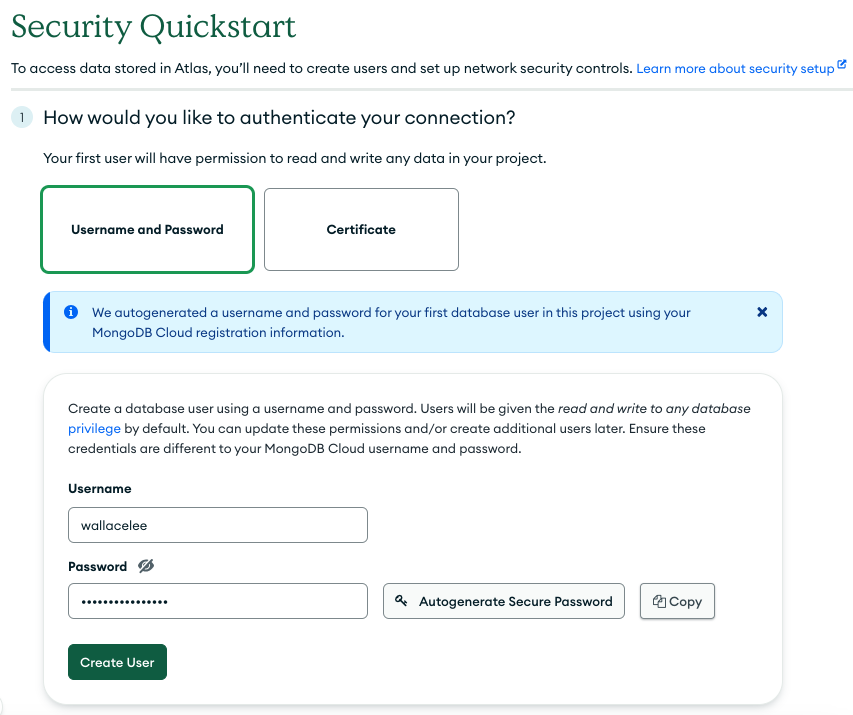
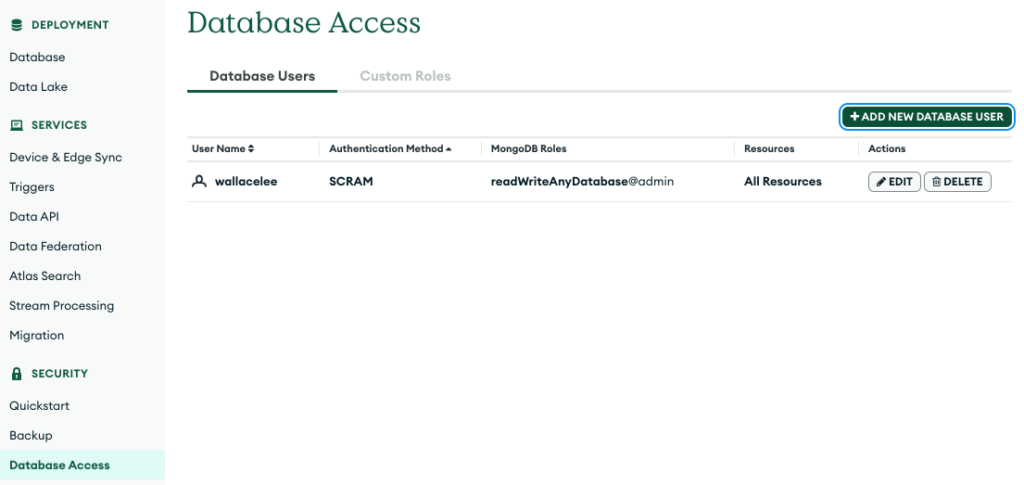
Under Database Access, add a database user with read and write access to the database.
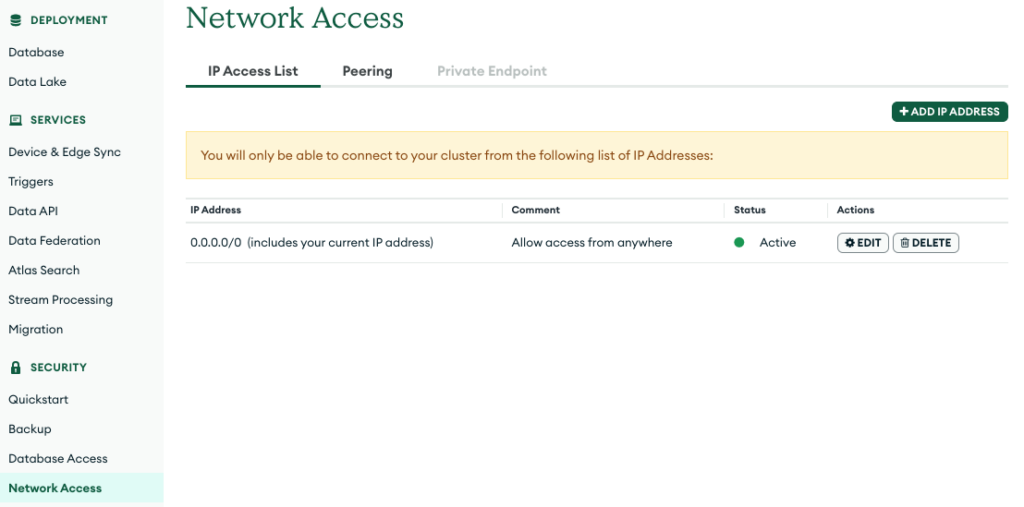
Under Network Access, add an entry to allow access from anywhere.
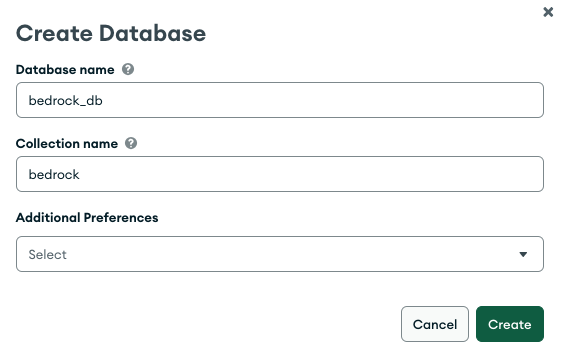
Create a database and collection in MongoDB Atlas cluster
Under Atlas Search, create a vector search index and select Altas Vector Search
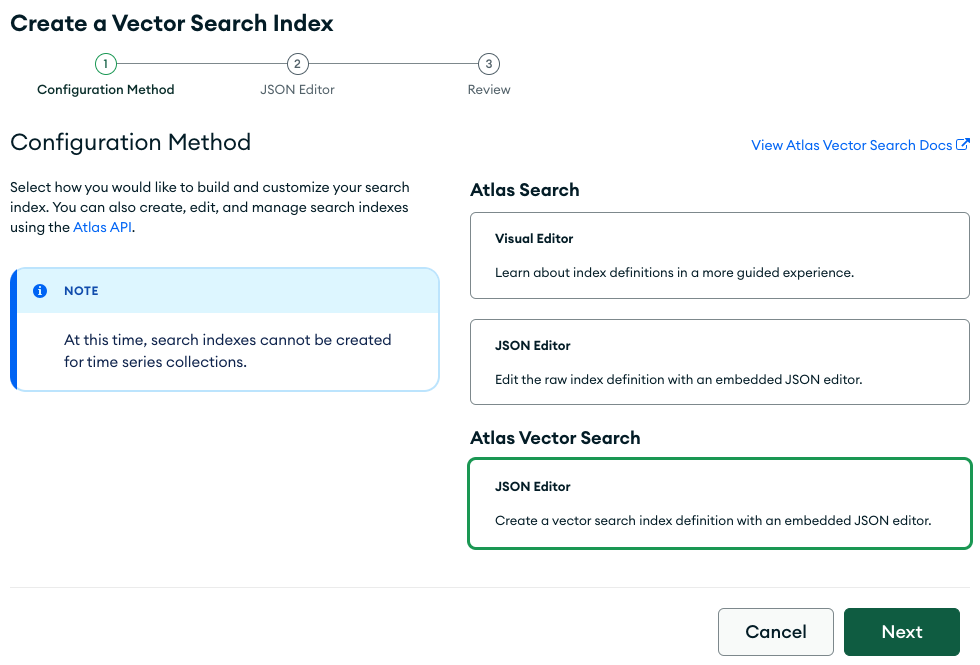
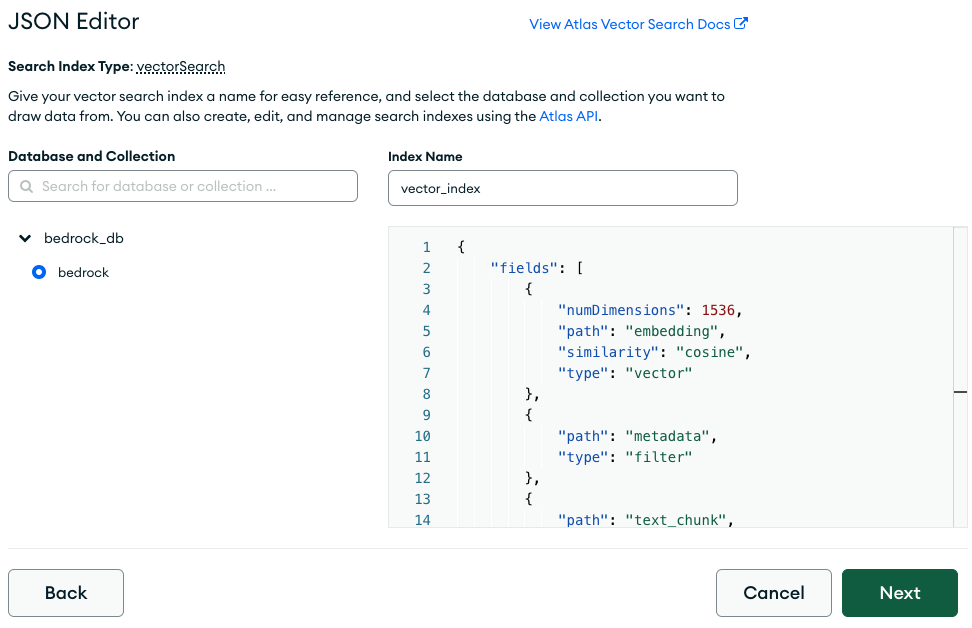
Select the database and collection where the embeddings are stored, then enter the following JSON in the index definition. These fields will need to match the fields in the AWS Bedrock knowledge base configuration.
{
"fields": [
{
"numDimensions": 1536,
"path": "bedrock_embedding",
"similarity": "cosine",
"type": "vector"
},
{
"path": "bedrock_metadata",
"type": "filter"
},
{
"path": "bedrock_text_chunk",
"type": "filter"
}
]
}
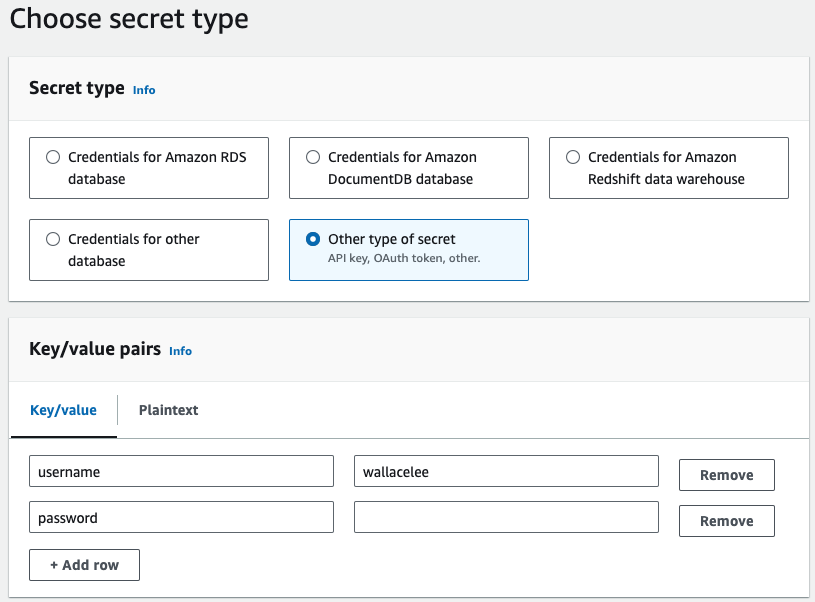
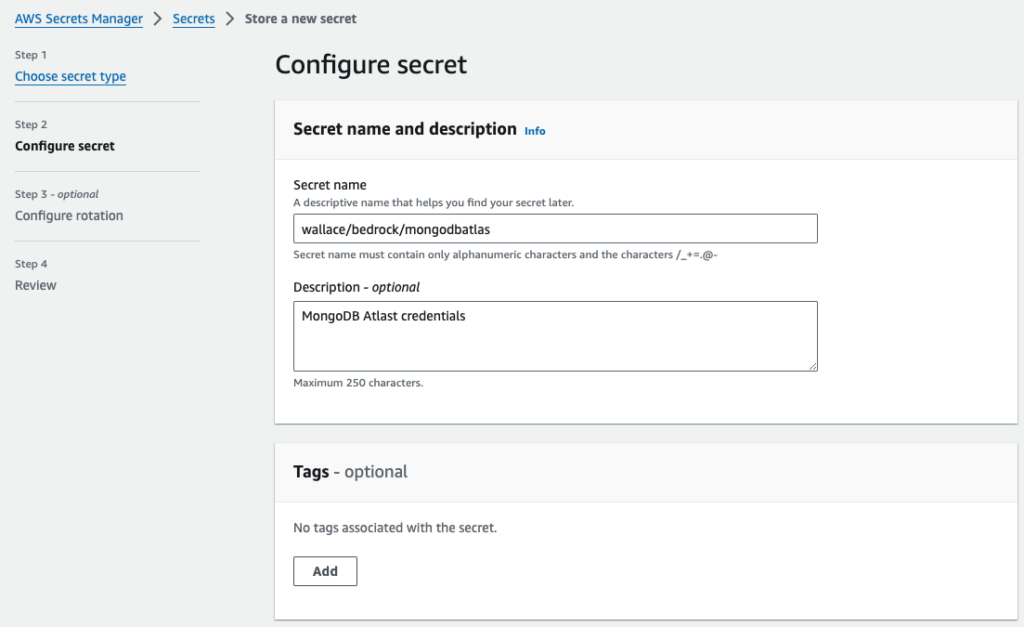
Now that our vector database is created, we want to store our MongoDB database username and password to AWS Secrets Manager for enhanced security. Go to Secrets Manager console and choose ‘Store a new secret’.
Let’s go back to AWS Bedrock console and continue the MongoDb configuration setup.
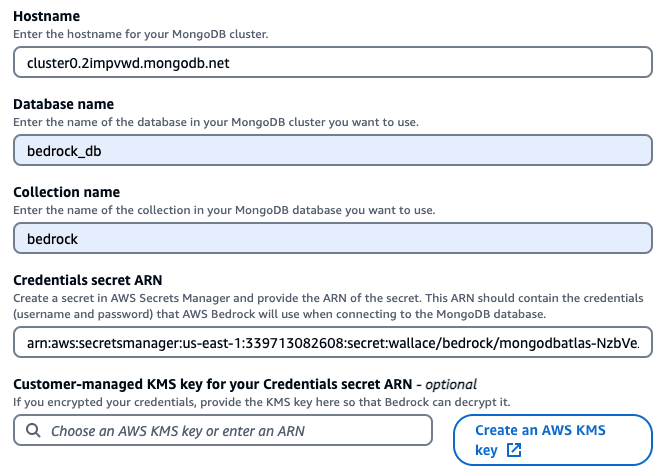
- Hostname: <mongodb cluster hostname>
- Database name: bedrock_db
- Collection name: bedrock
- Credentials secret ARN: Use the ARN from database credentials in AWS Secrets Manager
- Vector search index name: vector_index
- Vector embedding field path: bedrock_embedding
- Text field path: bedrock_text_chunk
- Metadata field path: bedrock_metadata

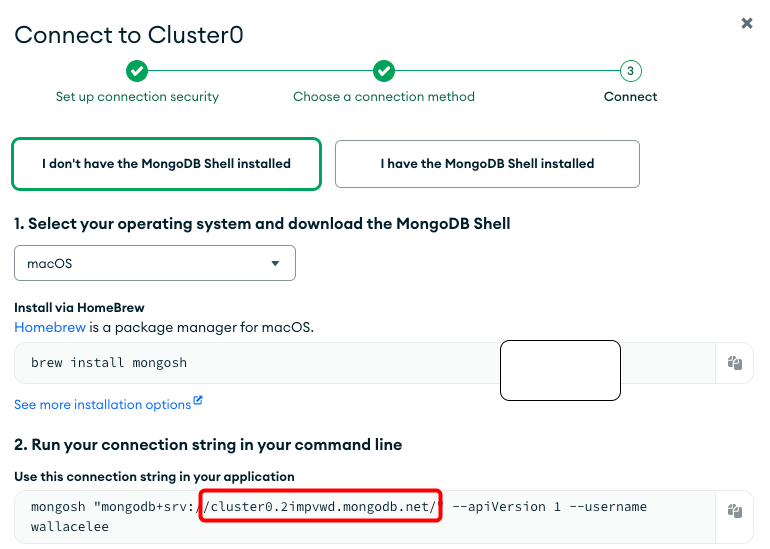
Hostname can be obtained from the connection string in MongoDB Atlas’s Cluster Overview->Connect->Shell
It takes a few minutes to create the knowledge base.
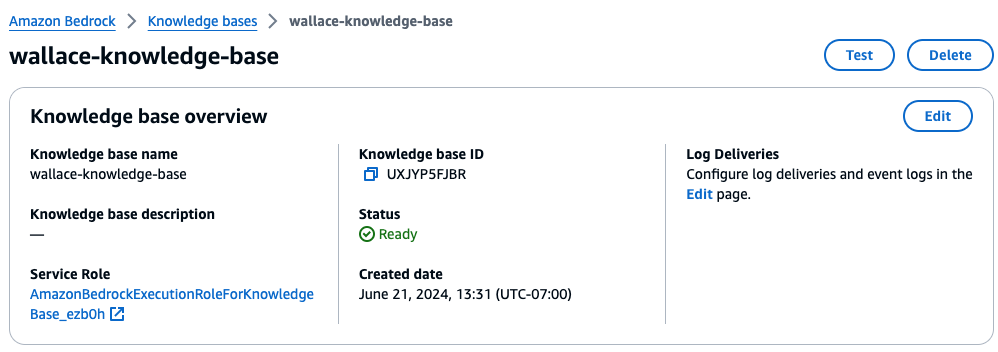
To ensure our data source remains current, we need to synchronize it either periodically or each time new documents are uploaded to the S3 bucket.
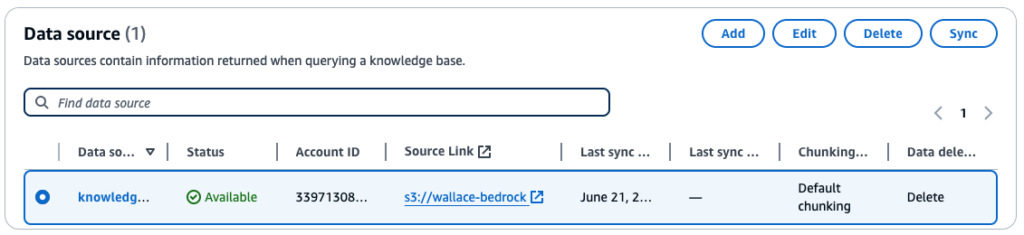
Create a AWS Bedrock Agent
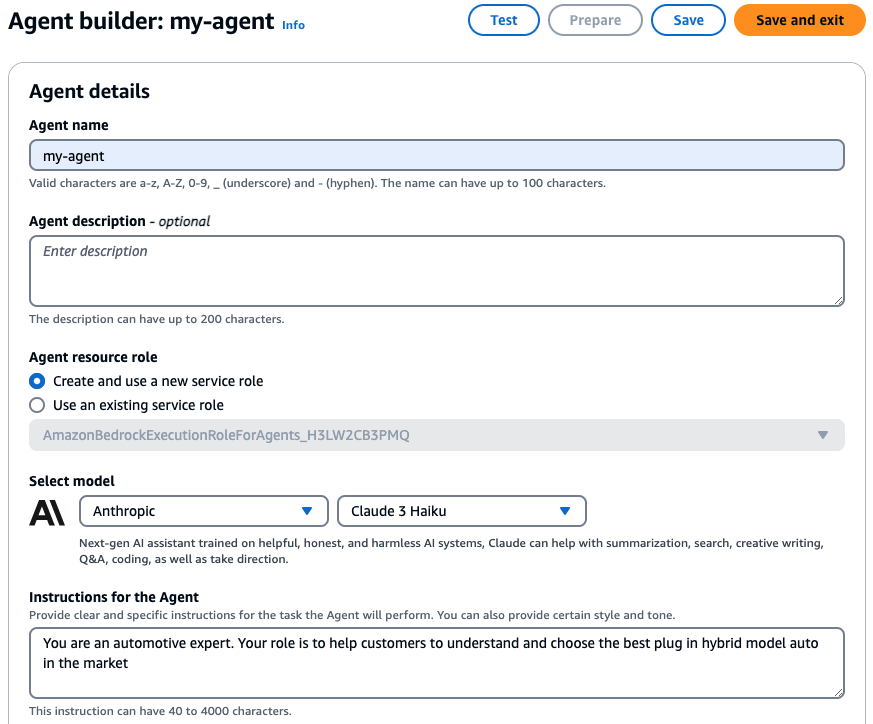
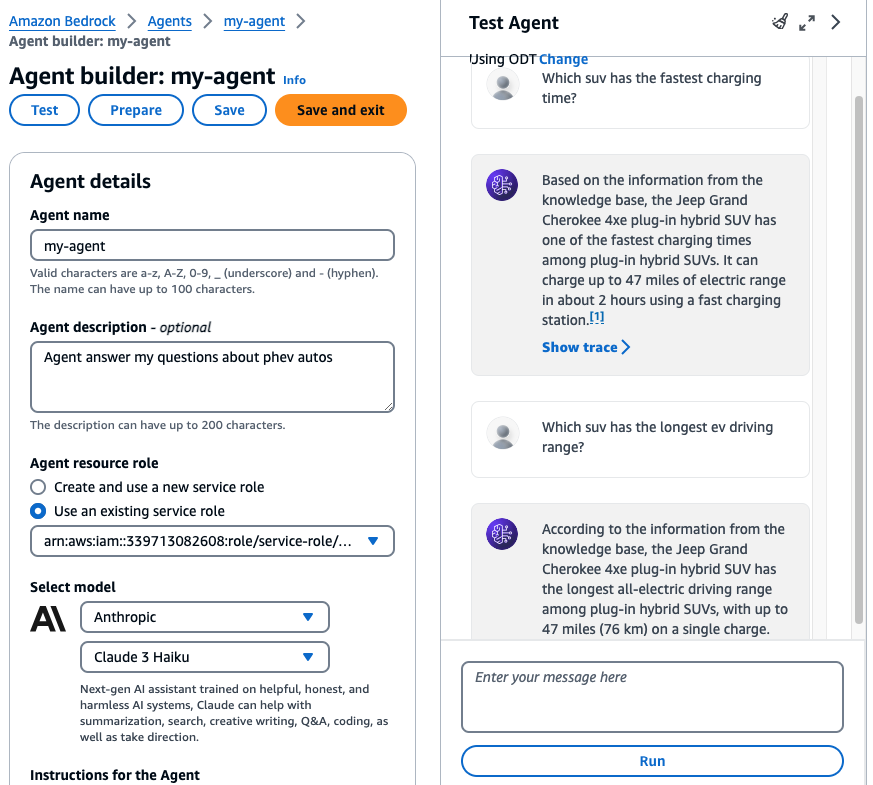
In order to query the knowledge base, we need to create a Bedrock Agent. Go to AWS Bedrock console, choose Agents and select Create Agent. I want the agent to answer my questions like an expert in the automotive industry and help me choose the best SUV model.
- Select model: Anthropic Claude 3 Haiku
- Instructions for agent: You are an automotive expert. Your role is to help customers to understand and choose the best plug in hybrid model auto in the market
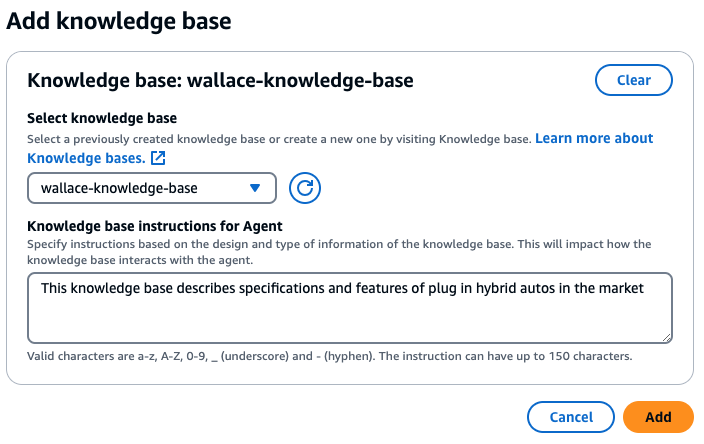
Add the knowledge base containing the catalogues and brochures to the agent.
Now I can ask the agent questions like ‘Which model has the fastest charging time?‘ or ‘Which suv has the longest ev driving range?‘
Building a RAG Chatbot
With Amazon Bedrock API, I can make a chatbot and embed it to a website and interact with my knowledge base. This can be useful for a variety of use cases like providing customer service with product specific help to customers, or legal advice by retrieving relevant case laws, statutes, and legal documents.

Clean Up
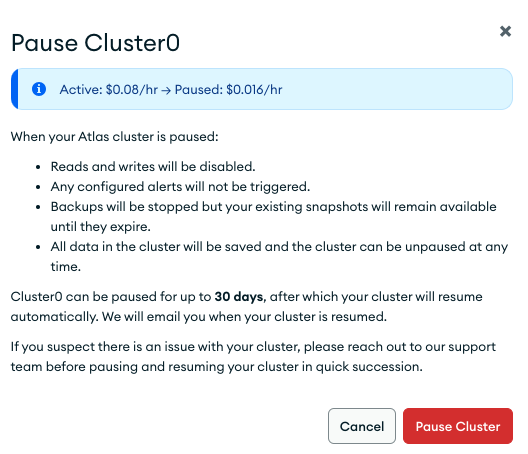
When we are done experimenting with RAG, we can either pause the MongoDB Atlas cluster to save some running cost, or terminate it completely.
Conclusion
This article demonstrates how to easily access AI models like Amazon Titan and Antropic Claude 3 using AWS Bedrock and MongoDB Atlas. Thank you for reading, and I hope you found it helpful.



